Introduction
Implementing the Retrieval-Augmented Generation (RAG) framework has opened a new world of possibilities in business intelligence. By indexing vast business datasets, RAG enables companies to access insights with unprecedented speed and accuracy—or at least, that’s the goal. However, as powerful as this framework is, it sometimes falls short of understanding the questions posed by its users. This article explores the complexities of context selection within the RAG framework, delving into why these misunderstandings occur and how they can be addressed.
Business User: But I am asking a simple question why can the RAG not answer it? …
AI Expert: A simple question often leads to a simple answer, but not necessarily the right answer. To provide an accurate response, we need more context to understand the intent behind your question.
Semantic discord
How Context is Retrieved
In the world of RAG, context retrieval is the cornerstone of generating accurate and relevant responses. The process involves sifting through vast datasets to find the most relevant pieces of information that match a user’s query. RAG utilises vectorised data and semantic similarity to determine which chunks of data are most relevant to the query context.
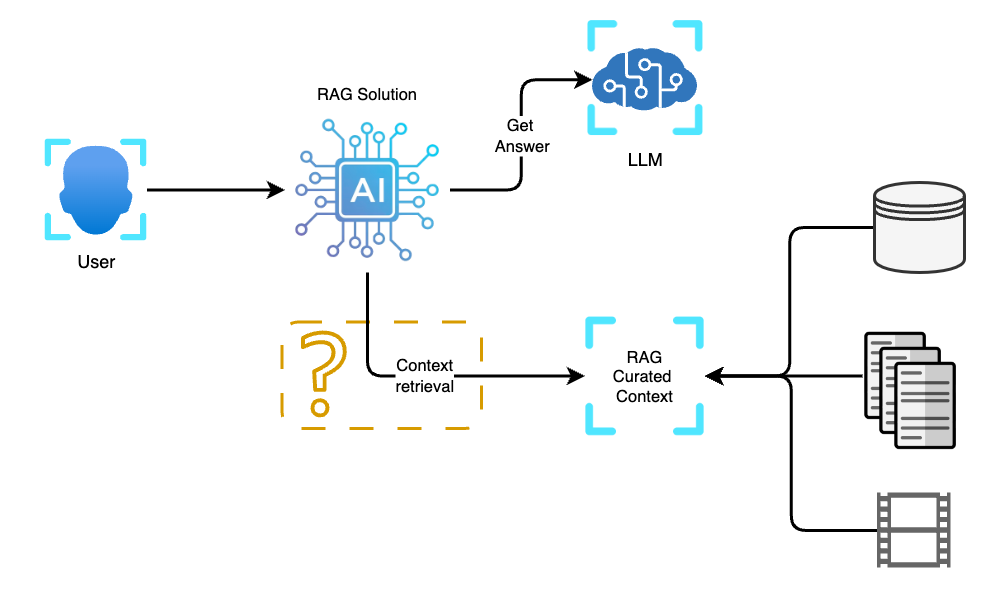
For example, if a business user asks, “What are the projected sales for Q4?” the RAG system needs to navigate through various datasets, including sales reports, market forecasts, and financial summaries. It must then determine which of these data points best aligns with the question. The magic lies in the system’s ability to understand the nuances and subtleties of natural language to pinpoint the right context.
Why It Fails
Despite its advanced capabilities, RAG can sometimes misinterpret the context needed for a given query. This issue often arises because the system depends on the data it has been trained on and the parameters set by its designers. Suppose the training data is not comprehensive or the parameters are not fine-tuned. In that case, the RAG system may pull information that is semantically similar but contextually irrelevant to the question at hand.
Consider a scenario where a user asks, “Are we forecasted to see a profile this year?” If the RAG system has been fed with data prioritising sales numbers and market analyses, it might overlook crucial updates or policy changes directly impacting this query. This disconnect illustrates how easily the right answer can be lost amidst semantically similar but contextually divergent data.
There’s also the challenge of vague or broad user queries. For instance, a user might ask, “What are the policies related to green energy?” without providing specifics like the relevant time period, geography, or domain. When a RAG system has data spanning all these dimensions, it’s like trying to hit a moving target when the query’s lack of precision, forcing the system to pull in context that might technically fit but doesn’t align with the user’s actual intent. This gap between what the user envisions and what the system retrieves highlights the need for both better user query formulation and smarter contextual refinement within RAG solutions.
How We Can Improve the Context Retrieved
Improving context retrieval in RAG systems involves several key strategies, such as expanding and diversifying training datasets, refining algorithms for context matching, and optimizing question and answer management. As the breadth of data sources grows, so too does the complexity of retrieving relevant context—making robust strategies an essential part of any successful implementation.
A strong emphasis on context retrieval strategies, combined with a focused training phase, can significantly enhance a RAG system’s ability to discern the true intent behind user queries. This leads not only to more accurate answers but also to a system better aligned with the unique needs of its users. However, there’s no one-size-fits-all solution; the strategies that will deliver the most value depend on the specific use case and operational environment.
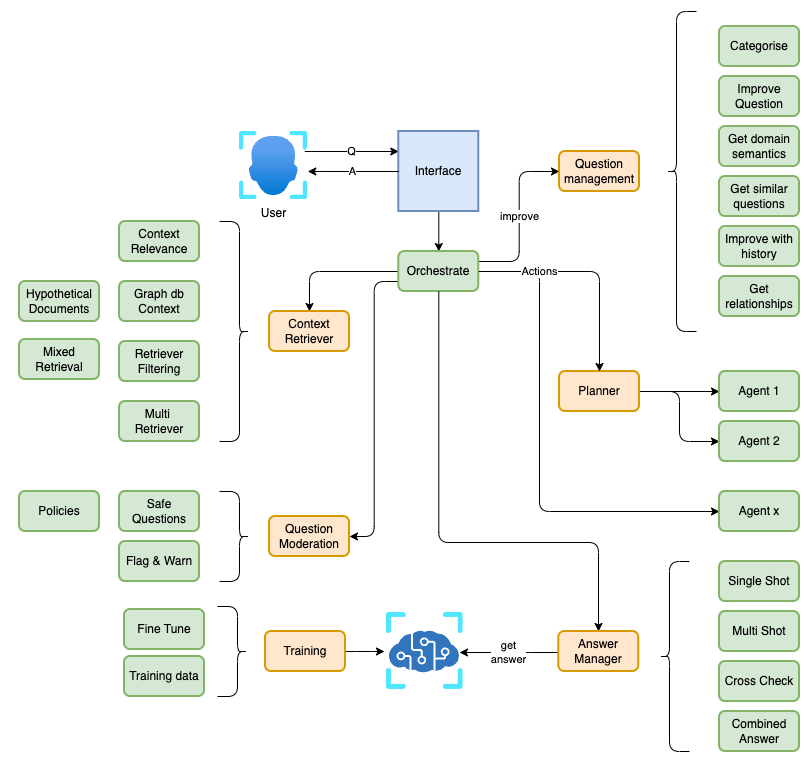
While this article serves as an introduction to the common pitfalls in RAG context retrieval, the possibilities for improvement are vast. To illustrate, I’ve included the following diagram outlining some of the many approaches available to enhance RAG responses. Consider it a starting point for your journey toward more effective and tailored solutions.