Sure, I can build you an AI RAG so that you can unlock your corporate knowledge and give all of your employees the uplift that will take your business to the next level …
Oh, you also want me to make sure its production hardened and it adheres to all your corporate policies and procedures. Ok lets start again, we need to plan this out.
Said no one ever …
This is the next stop on my AI adventure! Hot on the heels of “Navigating the AI Frontier: My Adventures with the RAG Framework,” we’re now delving into what I’ve experienced with uplifting my little homebrew solution and how to scale it up for an enterprise client. Let us imagine this is like upgrading from your homemade tricycle to your first ever Elon Musk electric car: doable but you’re going to need a better garage (and staff if we are going to make more than one car).
This article aims to provide you with sufficient contextual knowledge to engage in architectural discussions confidently and perhaps with a hint of flair. Typically the initial step involves outlining the essential architecture components that you should take into account, irrespective of the AI path you choose to pursue.
But first, how will the interaction from a human or system look like in this space? I like to have this context before I start, very businessy I know, so let’s imagine that the RAG framework I experimented with now needs to move to an enterprise, here is how I see it:
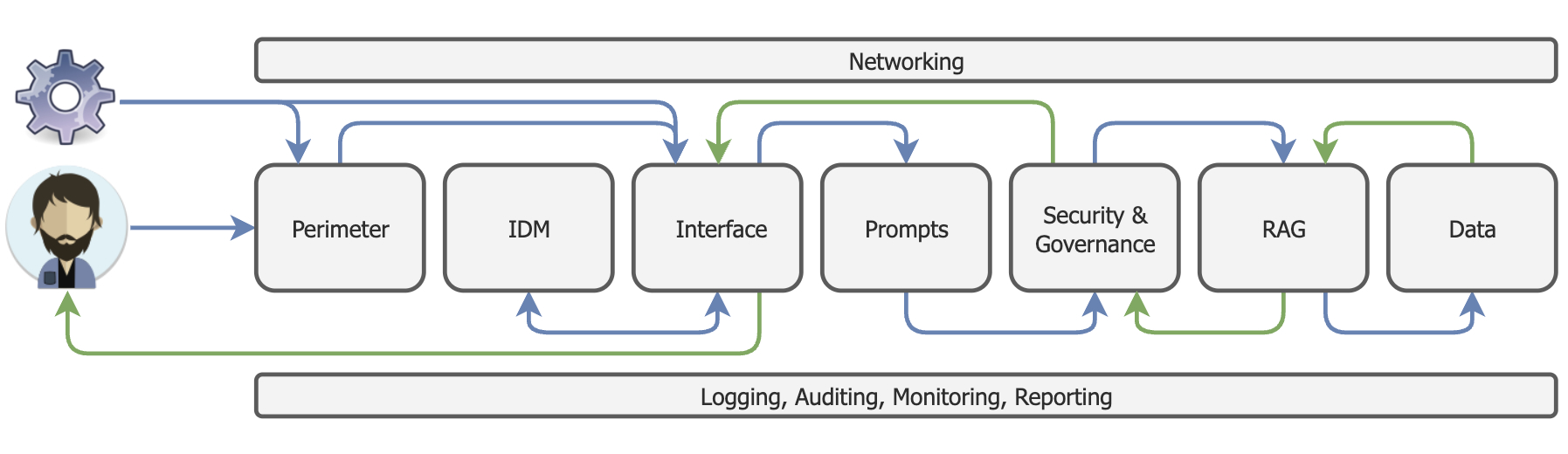
As the diagram shows, we still need to consider the perimeter controls that govern safe access to any solution we build. The interfaces (either a human UI or System API) will need to be established, and then we move into the AI space with prompting and AI Governance. Finally, we get to the real value where we establish the RAG and the supporting data.
So now that we have the interaction of a single use case, let’s kick things off with a diagram that lays out the major components from a bird’s-eye view, but expanded to consider any AI implementation.
AI Reference Architectural Components
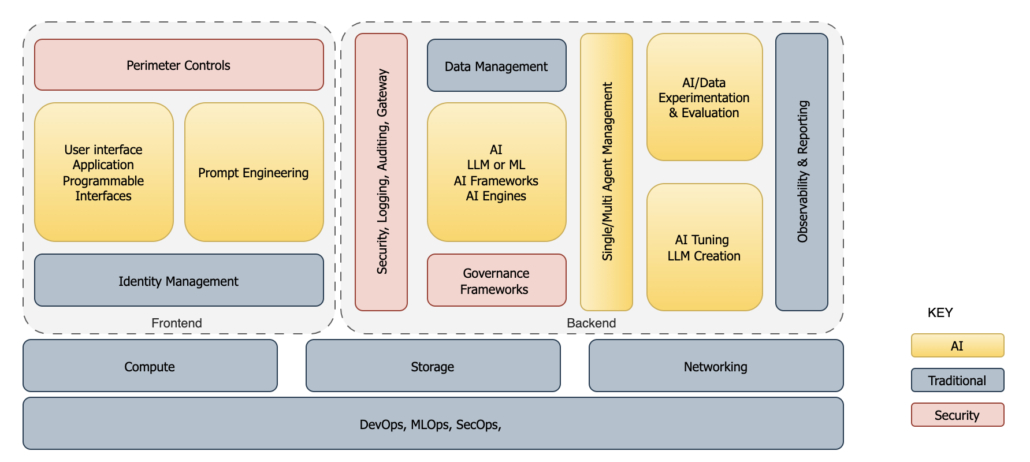
In the above diagram, I’ve divided the components into AI-specific and traditional solution components to highlight that enterprise-level AI doesn’t float in isolation but instead integrates with standard building blocks.
When I built my first RAG system, it was a humble setup on my local machine, utilizing online services like OpenAI and an S3 bucket, with the context Vector Store running locally. This setup was fantastic for learning AI’s quirks, and the ability to tweak and iterate swiftly was just what I needed. But scaling this to a production solution with larger data requirements and payloads, while sticking to enterprise policies, was another beast entirely. Let’s just say it was a technological throwaway, as most PoC are. The lessons learned were golden, but the tech stack? Not so much.
The next logical leap is to harness our enterprise expertise to elevate the solution for a business environment. This is always an opinionated process—I’ve yet to meet an architect who nods in agreement with an initial proposal without wanting to join the expedition. Think of it like assembling a merry band of adventurers who all want a say in charting the direction we are to take to find the treasure.
To spice things up a bit more, let’s introduce the various dimensions of an AI solution to appreciate the complexity of achieving AI maturity. Generally, I approach this through phased delivery of corporate initiatives, all depending on the clients I visit. Are they already AI-savvy? Midway through their AI journey? Have they begun upskilling their staff and pondering the policies and processes needed to govern this thrilling new technology?
AI Solution Maturity Considerations
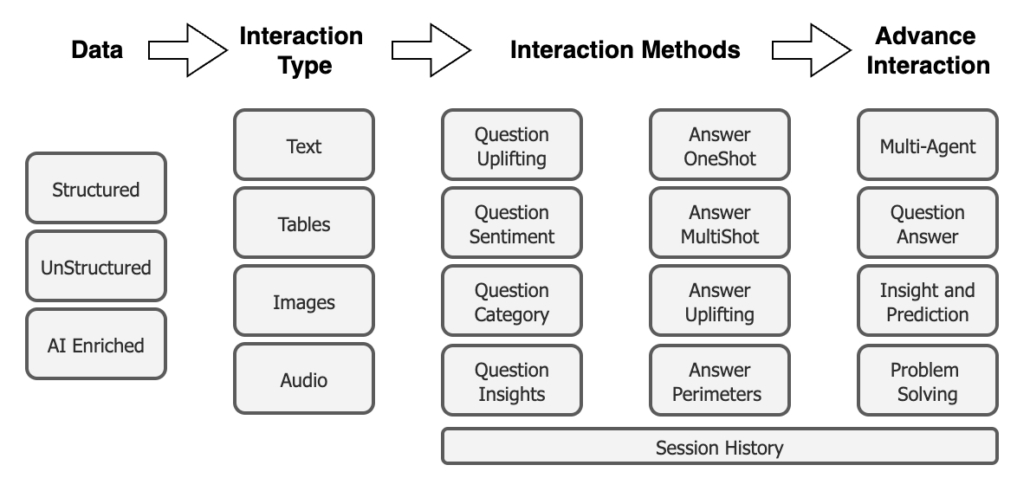
The path to maturity is a continuous journey marked by continuous progress, revealing fresh perspectives and possibilities at every turn. Throughout this expedition, numerous elements play a role, among them architectural factors like Data Management patterns. These patterns hold significant importance in upholding consistency across diverse interaction formats and in adjusting the structure of the RAG to enable the seamless coordination of different interaction techniques, like uplifting questions. Therefore, it is essential to perceive mature uplift as an integral part of the journey, encompassing architectural enhancements to address emerging needs as we progress through the maturity phases.
Look, if it were easy, we’d all have AI everywhere by now, right? Although AI’s ideas and potential have been around for ages, it’s only in the last 2-3 years that most enterprises have seriously started considering how to introduce this transformative technology. So don’t feel bad—we’re all navigating this new realm together, hashing out similar solutions and having lots of in-depth discussions.
Wrapping up this brief introduction to AI Architecture Components, I hope we’ve painted a broad-stroke picture of the many parts involved. Next, we’ll dissect each component and detail how they all come together to drive outcomes that can uplift and revolutionise our businesses, positioning us to compete better tomorrow. I’ll pick a use case and see how it can be realised with the above consideration.
Post Article Note
All the above sits in the pre-delivery dream state where we design and think about what we need to ensure success. To achieve the interactions (human or system) that will innovate and elevate the business we are calling out, each journey at a client still needs to consider the old chestnut of planning, designing, validating, implementing and ongoing management, to realise an enterprise outcome(s). This is crucial to ensure we add value and don’t contribute to the corporate “not delivering” pile.